LeetCode-第438场周赛
本文最后更新于:2025年2月23日 晚上
LeetCode-第438场周赛
第一次参加LeetCode周赛,只完成了前两题。第三题一直超时
排名 868/2401 豆包1.5 Pro水平
Q1. 判断操作后字符串中的数字是否相等Ⅰ
题目描述
给你一个由数字组成的字符串 s 。重复执行以下操作,直到字符串恰好包含 两个 数字:
- 从第一个数字开始,对于 s 中的每一对连续数字,计算这两个数字的和 模 10。
- 用计算得到的新数字依次替换 s 的每一个字符,并保持原本的顺序。
如果 s 最后剩下的两个数字 相同 ,返回 true 。否则,返回 false。
示例 1:
输入: s = “3902”
输出: true
解释:
一开始,s = “3902”
第一次操作:
(s[0] + s[1]) % 10 = (3 + 9) % 10 = 2
(s[1] + s[2]) % 10 = (9 + 0) % 10 = 9
(s[2] + s[3]) % 10 = (0 + 2) % 10 = 2
s 变为 “292”
第二次操作:
(s[0] + s[1]) % 10 = (2 + 9) % 10 = 1
(s[1] + s[2]) % 10 = (9 + 2) % 10 = 1
s 变为 “11”
由于 “11” 中的数字相同,输出为 true。
示例 2:
输入: s = “34789”
输出: false
解释:
一开始,s = “34789”。
第一次操作后,s = “7157”。
第二次操作后,s = “862”。
第三次操作后,s = “48”。
由于 ‘4’ != ‘8’,输出为 false。
提示:
3 <= s.length <= 100s 仅由数字组成。
题解
数据范围小,模拟即可
1 | |
Q2. 提取至多K个元素的总和
给你一个大小为 n x m 的二维矩阵 grid ,以及一个长度为 n 的整数数组 limits ,和一个整数 k 。你的目标是从矩阵 grid 中提取出 至多 k 个元素,并计算这些元素的最大总和,提取时需满足以下限制:
- 从 grid 的第 i 行提取的元素数量不超过 limits[i] 。
返回最大总和。
示例 1:
输入:grid = [[1,2],[3,4]], limits = [1,2], k = 2
输出:7
解释:
从第 2 行提取至多 2 个元素,取出 4 和 3 。
至多提取 2 个元素时的最大总和 4 + 3 = 7 。
示例 2:
输入:grid = [[5,3,7],[8,2,6]], limits = [2,2], k = 3
输出:21
解释:
从第 1 行提取至多 2 个元素,取出 7 。
从第 2 行提取至多 2 个元素,取出 8 和 6 。
至多提取 3 个元素时的最大总和 7 + 8 + 6 = 21 。
提示:
n == grid.length == limits.lengthm == grid[i].length1 <= n, m <= 5000 <= grid[i][j] <= 10^50 <= limits[i] <= m0 <= k <= min(n * m, sum(limits))
题解
排序
1 | |
Q3. 判断操作后字符串中的数字是否相等Ⅱ
题目与Q1一致,但数据范围更大
3 <= s.length <= 10^5
解法一-组合数求解
1 | |
1 | |
超出时间限制,优化组合数阶乘求解和两次遍历
1 | |
还是超出了时间限制
全服第一解法
看不懂
1 | |
1. 计算组合数模 5 和模 2
在这个实现中,组合数的计算被分成了两部分:模 2 和模 5。组合数模 10 可以通过结合模 2 和模 5 的结果来求得,类似于中国剩余定理的思路。具体地:
- 模 2:通过位操作来判断组合数的结果,
binom_mod2函数判断$C(n, k) \mod 2$ 的结果。这是因为对于二项式系数 $C(n, k)$,模 2 的结果仅仅由二进制表示中的某些特定规则决定。 - 模 5:计算组合数的模 5,通过预处理的
binom_mod5表来加速组合数的计算。这里使用了递推和分解的方法,避免了直接计算阶乘。
2. 组合数模 10 的计算
为了计算组合数的模 10,代码通过结合 binom_mod2 和 binom_mod5_func 的结果,并使用 combine_map 来映射组合数的模 2 和模 5 的值到模 10 的值。
binom_mod2用于计算组合数模 2。binom_mod5_func用于计算组合数模 5。通过递推和取模的方法,避免了直接计算大数阶乘。
之后,通过 combine_map,将 (mod 2, mod 5) 对应的组合数模 10 的结果提取出来。
3. 优化和预处理
- 预处理组合数:代码在开始时就预处理了组合数的模 5,保存在
binom_mod5表中。这样,在后续计算中就可以直接使用这些预计算的值,而不需要每次都重新计算组合数。 - 逐步计算:每轮计算组合数时,通过递推公式,逐步计算并更新组合数模 10 的结果。通过这样的方法,避免了重复计算,显著提高了效率。
4. 优化的关键步骤
- 合并模 2 和模 5 的结果:通过
combine_map映射模 2 和模 5 的组合结果到模 10。由于模 2 和模 5 对组合数的影响各自独立,这个方法巧妙地将两者的结果结合起来。 - 递推而不是阶乘计算:通过递推计算组合数的模 5,避免了直接计算阶乘,这对于大规模数据尤其有效。
- 位操作判断组合数模 2:通过位操作实现 $C(n, k) \mod 2$的计算,这在处理二项式系数时非常高效。
5. 算法分析
时间复杂度:该算法的时间复杂度主要由两部分组成:
- 预处理阶段:计算组合数模 5,时间复杂度为
O(n),其中n是输入字符串的长度。
- 预处理阶段:计算组合数模 5,时间复杂度为
- 计算阶段:遍历字符串并计算组合数的结果,时间复杂度为
O(n),因为每次更新的计算量是常数时间。
Q4. 正方形上的点之间的最大距离
题目描述
给你一个整数 side,表示一个正方形的边长,正方形的四个角分别位于笛卡尔平面的 (0, 0) ,(0, side) ,(side, 0) 和 (side, side) 处。
同时给你一个 正整数 k 和一个二维整数数组 points,其中 points[i] = [xi, yi]表示一个点在正方形边界上的坐标。
你需要从 points 中选择 k 个元素,使得任意两个点之间的 最小 曼哈顿距离 最大化 。
返回选定的 k 个点之间的 最小 曼哈顿距离的 最大 可能值。
两个点 (xi, yi) 和 (xj, yj) 之间的曼哈顿距离为 |xi - xj| + |yi - yj|。
示例 1:
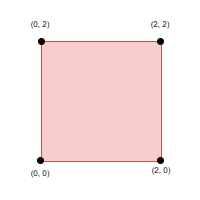
输入: side = 2, points = [[0,2],[2,0],[2,2],[0,0]], k = 4
输出: 2
解释:
选择所有四个点。
示例 2:
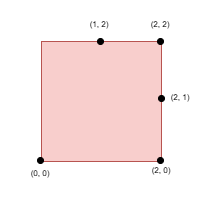
输入: side = 2, points = [[0,0],[1,2],[2,0],[2,2],[2,1]], k = 4
输出: 1
解释:
选择点 (0, 0) ,(2, 0) ,(2, 2) 和 (2, 1)。
示例 3:
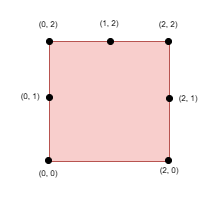
输入: side = 2, points = [[0,0],[0,1],[0,2],[1,2],[2,0],[2,2],[2,1]], k = 5
输出: 1
解释:
选择点 (0, 0) ,(0, 1) ,(0, 2) ,(1, 2) 和 (2, 2)。
提示:
1 <= side <= 10^94 <= points.length <= min(4 * side, 15 * 103)points[i] == [xi, yi]- 输入产生方式如下:
points[i]位于正方形的边界上。- 所有
points[i]都 互不相同 。
4 <= k <= min(25, points.length)
题解
没来得及做
全服第一解法
- 将所有点映射到环上的参数值,并排序。
- 复制一份点集并加上
4*side,用于处理环的循环特性。 - 使用二分法在范围
[0, 2*side]内搜索最大可能的最小距离。
1 | |