NLP-Spell Correction
本文最后更新于:2024年10月26日 上午
Spell Correction
拼写检查任务,实现语言模型和通道模型,并利用tkinter实现GUI
I.Environment
Python 3.10.9
Package: nltk 3.7 and numpy 1.26.4
II.Theory
Spell-checking involves distinguishing between non-word errors and real-word errors. Non-word errors occur when a word is spelled incorrectly to the extent that it does not exist, such as spelling “giraffe” as “graffe.” Real-word errors, on the other hand, involve correctly spelled words that are used incorrectly within a given context.
Detection of non-word spelling errors primarily relies on dictionary lookup to determine whether a word exists. Correcting non-word errors typically involves two main steps: first, generating candidate words that are similar to the misspelled word and correct; second, selecting the best correction from these candidates. The selection of the best correction can be achieved through methods such as calculating the weighted edit distance between the misspelled word and each candidate word, choosing the candidate with the shortest distance as the correction, or calculating noisy channel probabilities and selecting the highest probability candidate.
Handling real-word spelling errors involves generating a set of candidate corrections for each word w. Candidates can be generated based on similar pronunciation or spelling to w, ensuring that w itself is included in the candidate set. The best correction is then chosen from these candidates, often using methods like edit distance to select the candidate with the smallest distance from w, or applying a noisy channel model to choose the candidate with the highest posterior probability. These approaches are combined to select the candidate with the highest probability among candidates with equal edit distances.
This framework ensures effective handling of spelling errors in natural language processing applications.
III.Data
Training corpus
Reuters Corpus
Test dataset
testdata.txt
IV.Model Development
Language model
Language models evaluate the naturalness and grammatical correctness of sentences by assessing the probability of word occurrences in text. The sentence probability calculation formula is derived from the chain rule.
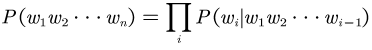
Introducing the Markov assumption, given the previous k words, each word’s generation depends solely on these k preceding words. The formula then transforms into
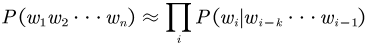
In natural language processing, the method where each word’s generation depends on the preceding N words is called N-gram. The 0th order is Unigram, 1st order is Bigram, and 2nd order is Trigram.
In language modeling, the issue of encountering probabilities of zero often arises, necessitating the use of smoothing methods. Here, I combine Add-k smoothing and interpolation smoothing for handling this issue.
interpolation smoothing:
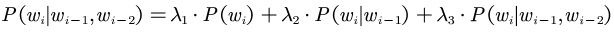
Among them : 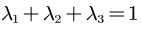 .
.
For calculating unigram, bigram, and trigram probabilities, we use Add-k smoothing. 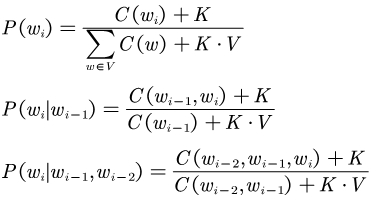
Edit Distance
Based on edit distance, the system can generate a list of candidate words similar to the original word. By constraining the edit distance within a reasonable range, we ensure that the generated candidate words include possible correct spelling forms. We filter out candidate words where the edit distance is less than or equal to 2 to obtain the list of candidates.
Noisy channel model
The system combines the candidate word list generated using edit distance with a noisy channel model to weight and evaluate the probability of each candidate word. This approach helps to exclude spelling suggestions that are unreasonable in context and improves the accuracy of selecting the correct correction by the system.
Assume word x has a spelling error. Now, to find the best candidate from the set V, the following calculation method can be used.
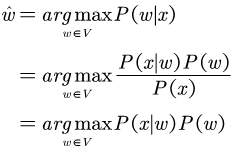
Where P(x|w) is derived from the noisy channel model, and P(w) is derived from the language model.
The channel model also employs Add-k smoothing to smooth the probabilities.
V.Code Implementation
Data preprocessing
preprocessing(ngram, cate)
Read the vocabulary from vocab.txt, read and preprocess the test data from testdata.txt, and process the corpus to form n-gram information.
Load confusion matrix
Here, we use the data from the paper ‘A Spelling Correction Program Based on a Noisy Channel Model’
loadConfusionMatrix():
Obtain addmatrix, submatrix, revmatrix, and delmatrix respectively.
Language model
interpolated_language_model(gram_count, V, data, lambdas, K=0.0001)
Language model combining Add-k smoothing and interpolated smoothing
Edit distance
editType(candidate, word)
Identify the type of edit relative to the original word for candidate words.

Retrieve candidate words
get_candidate(trie, word, edit_distance=2)
Retrieve words from the dictionary with an edit distance of less than or equal to 2 as candidate words.

Noisy channel model
channelModel(x, y, edit, corpus, k=0.1)
Calculate channel model error probability

Perform spell correction
spell_correct(vocab, testdata, gram_count, corpus, V, trie, lambdas)
Perform spell correction on the test data, first addressing non-word errors, then handling real-word errors.
VI.Result
Obtained by multiple adjustments of various parameter values:
| Interpolated combination weights | Add-1 | Add-k |
|---|---|---|
| 0.90 0.05 0.05 | 82.9% | 88.8% |
| 0.05 0.90 0.05 | 85.5% | 89.2% |
| 0.05 0.05 0.90 | 85.4% | 89.2% |
| 0.01 0.80 0.19 | 85.6% | 89.7% |
| 0.20 0.30 0.50 | 84.8% | 89.3% |
| 0.10 0.30 0.60 | 85.3% | 89.5% |
| 0.10 0.60 0.30 | 85.2% | 89.4% |
| 0.40 0.40 0.20 | 84.3% | 89.2% |
The highest accuracy is 89.7%, with interpolated combination weights of 0.01, 0.80, and 0.19, using Add-k smoothing.
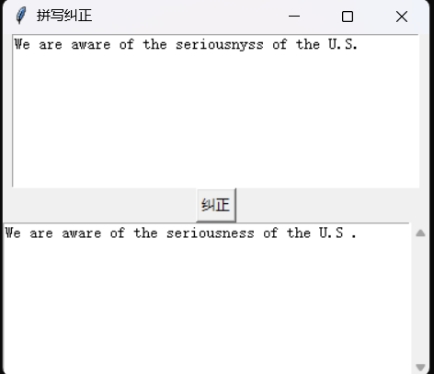
VII.GUI
The packaged executable file “main_script.exe” is located in “/GUI/dist/main_script”. Double-click to run it.
VIII.Reference
[1] Kernighan, M. D., Church, K., & Gale, W. A. (1990). A spelling correction program based on a noisy channel model. In COLING 1990 Volume 2: Papers presented to the 13th International Conference on Computational Linguistics.
[2] Jayanthi, S. M., Pruthi, D., & Neubig, G. (2020). Neuspell: A neural spelling correction toolkit. arXiv preprint arXiv:2010.11085.
[3] 如何写一个拼写纠错器 – how to write a spelling corrector-CSDN博客
[4] https://blog.csdn.net/qq_36134437/article/details/103146390
[5] NLP-拼写纠错(spell correction)实战_nlp correction插件-CSDN博客
IX. Code
main.py
1 | |
eval.py
1 | |
GUI.py
1 | |